Is the trial fully functional?
Yes. The 14-day trial gives you full product access — including all features, 4 user seats, and real pipeline compilation — so you can evaluate BoltPipeline on real SQL and real data.
What happens after the trial ends?
You can upgrade to the Starter plan to continue using BoltPipeline in production, or contact us to discuss Team, Growth, or Enterprise options.
What counts as a pipeline?
A pipeline is a logical group of up to 50 SQL statements that BoltPipeline compiles, validates, and manages as a unit — including execution order, lineage, SCD logic, and drift detection. We recommend the 50-SQL limit as a best practice for maintainability.
Why is there a 50-SQL limit per pipeline?
Beyond 50 SQL statements, human cognitive load for managing, debugging, and understanding a single pipeline degrades significantly. The limit is both a metering boundary and a best practice — splitting at natural domain boundaries improves lineage clarity and operational resilience.
What are the 4 included seats?
Every plan includes 4 user seats — one for each RBAC role: Viewer (read-only), Developer (upload SQL, edit pipelines), Operator (approve promotions, deploy), and Admin (manage teams, environments, users). Need more seats? Contact us.
Do you charge per query or per row?
No. BoltPipeline is priced per pipeline — predictable and aligned with the value delivered. No per-seat tax, no usage surprises, no per-row charges.
Can we add more users beyond 4?
Yes. Additional seats are available as an add-on for Team and Growth plans. Enterprise plans include unlimited users.
Do you support self-hosted deployments?
Yes. Enterprise plans support private, hybrid, and air-gapped deployments.
How does BoltPipeline run securely?
BoltPipeline uses a lightweight agent in your environment that executes pipelines inside your database. Your data never leaves your infrastructure. Only metadata flows to the Command Center.
How is BoltPipeline different from traditional ETL tools?
Traditional ETL tools move and transform data through external engines. BoltPipeline works after data lands — generating SCD pipelines, lineage, drift detection, and governance. All in-database, no proprietary runtime.
Does BoltPipeline replace existing transformation tools?
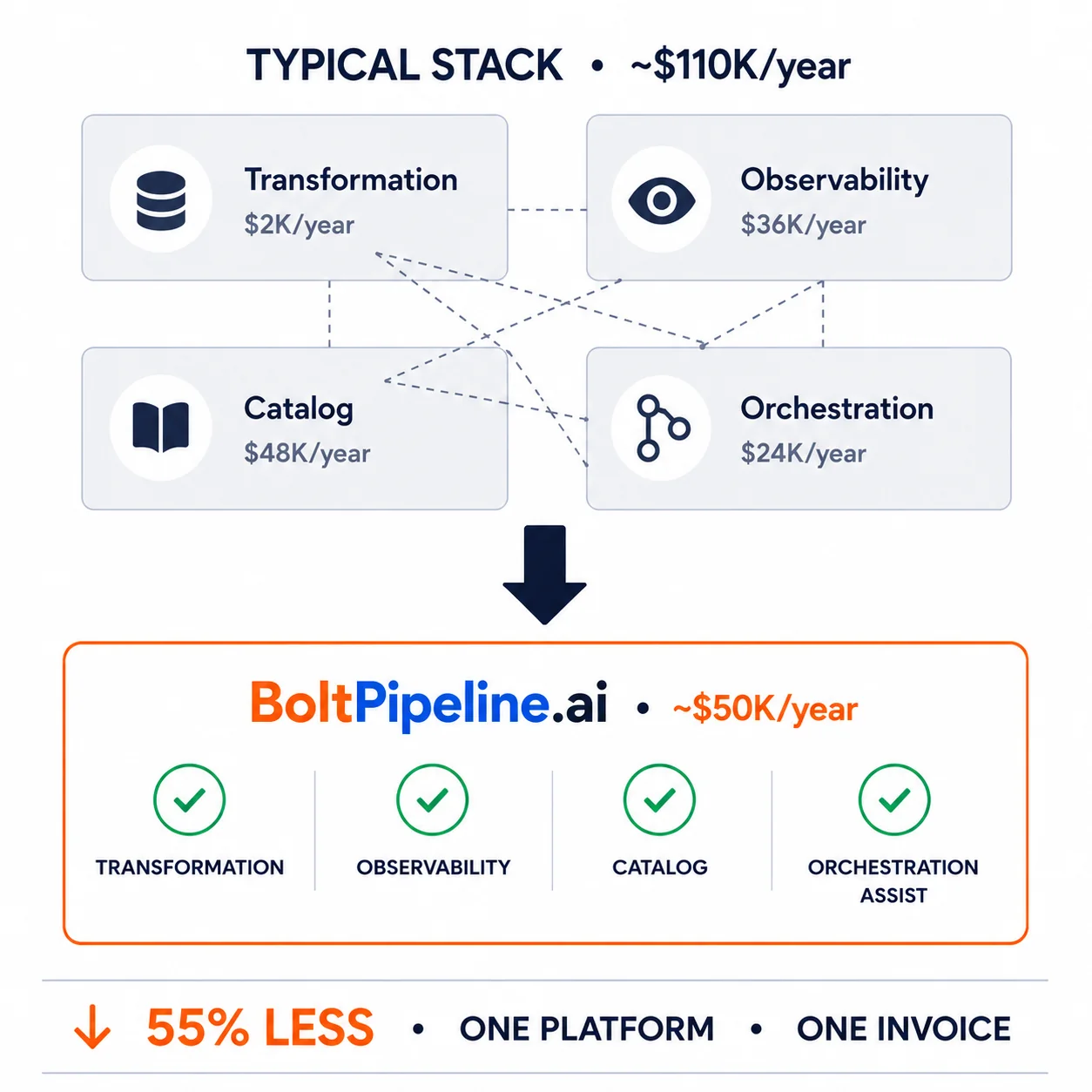
BoltPipeline can complement or replace existing SQL transformation workflows. It generates complete pipelines with SCD automation, lineage, drift detection, and governance built in — capabilities that typically require multiple products.
Does BoltPipeline ingest data?
No. BoltPipeline starts after data lands in your warehouse. It pairs with your existing ingestion tools like Fivetran, Airbyte, or Stitch.