Schemas & Semantics
- Type and compatibility checks
- Contract verification for renamed or removed fields
- Safe materialization across models
You write SQL — or your AI does. From there, the lifecycle takes over: SQL is parsed, validated, certified against your live database, and only then deployed to run. Every stage produces real artifacts. Every gate is enforced.
You write SQL. The platform handles compilation, validation, lineage, and deployment.
Author SQL business rules
Analyze structure, semantics, and dependencies
Profile data and establish baselines
Validate changes and detect drift with impact
Generate certified, executable pipeline artifacts
A simple, repeatable flow that separates authoring from implementation so teams move faster without sacrificing trust.
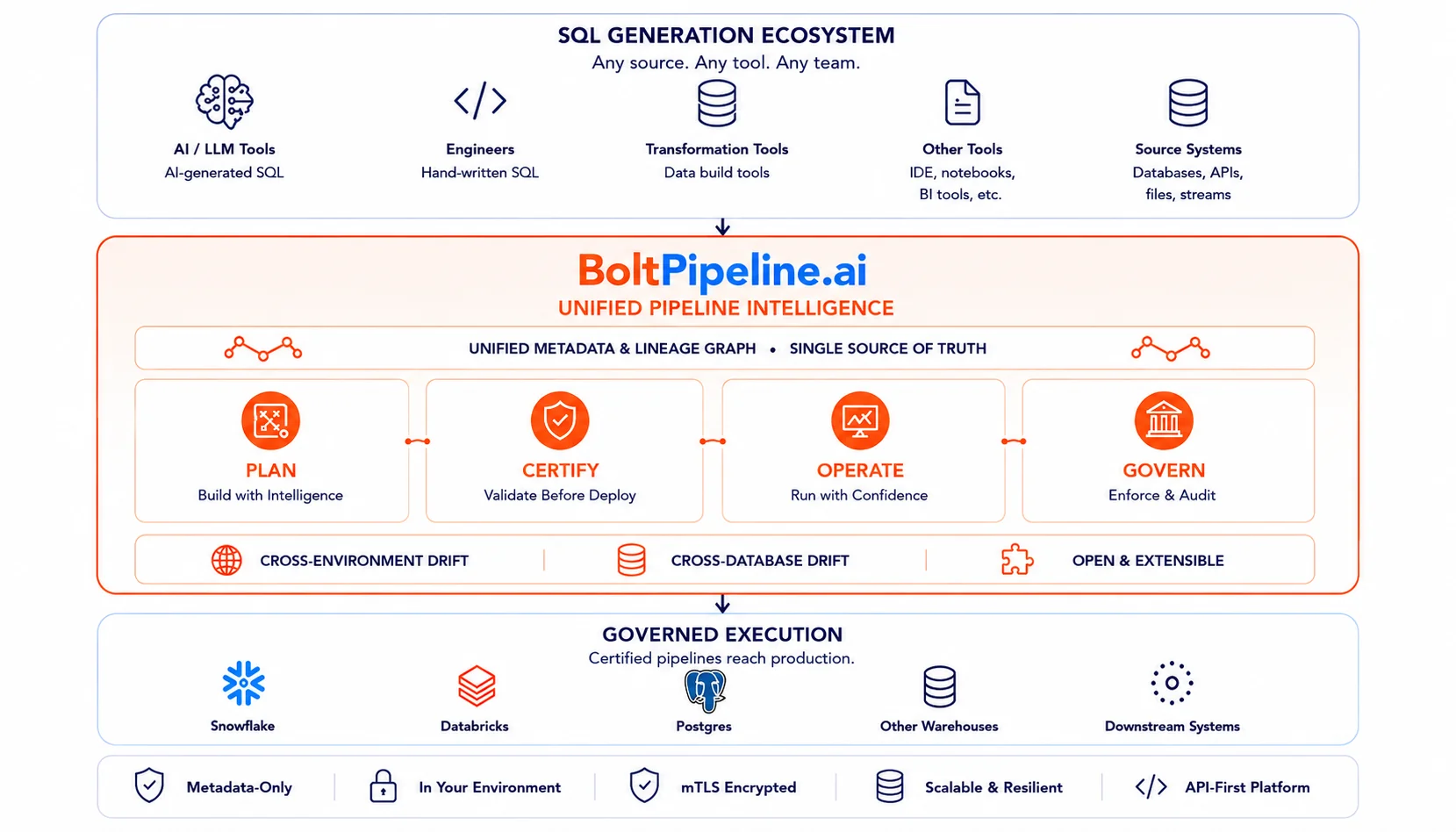
BoltPipeline is the unified control plane for SQL pipelines. Whatever generates your SQL — AI tools, dbt, your team, transformation frameworks — flows through BoltPipeline before reaching your warehouse. Four governed stages — Plan, Certify, Operate, Govern — backed by a unified metadata + lineage graph. Output: certified pipelines to Snowflake, Databricks, Postgres, and any warehouse.
SQL parsing and compilation. Lineage derivation. Dependency graphs. Impact prediction. Execution planning. SCD and schema automation. Author in plain SQL — the platform handles the rest.
30+ certification rules run against your live database. Schema and data validation. Lineage impact analysis. Drift and freshness checks. Environment comparison. Security and policy checks. Risk scoring and approval gates.
Orchestration and scheduling. Pipeline monitoring. Data freshness tracking. Post-deploy drift detection. Alerting and incident management. Performance and cost insights.
Ownership and stewardship. Data contracts and policies. Access and permissions. Audit logs and lineage. Compliance and standards. Change history and rollback.
BoltPipeline starts where your team already is: SQL. Engineers and analysts describe what the data should mean, not how to wire pipelines by hand.
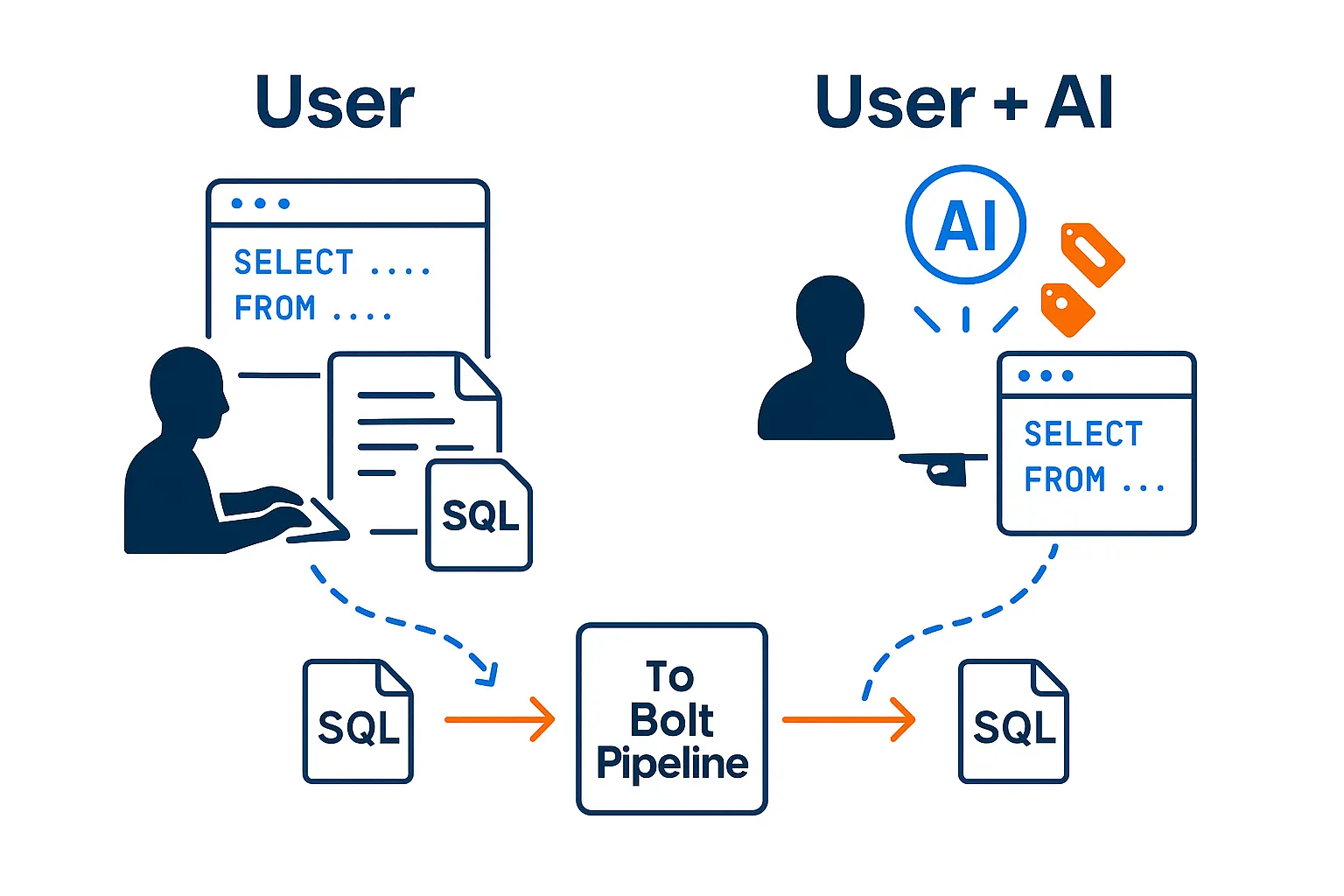

This is where BoltPipeline does the heavy lifting. The platform analyzes SQL intent, validates correctness, and surfaces issues before anything ships.
The output is a set of certified artifacts: executable SQL, validation results, lineage, profiles, and audit metadata — portable and customer-owned.
BoltPipeline does not replace your runtime. You deploy and operate pipelines where your data lives.
BoltPipeline provides visibility, safety signals, and governance context — without taking control away from your team.
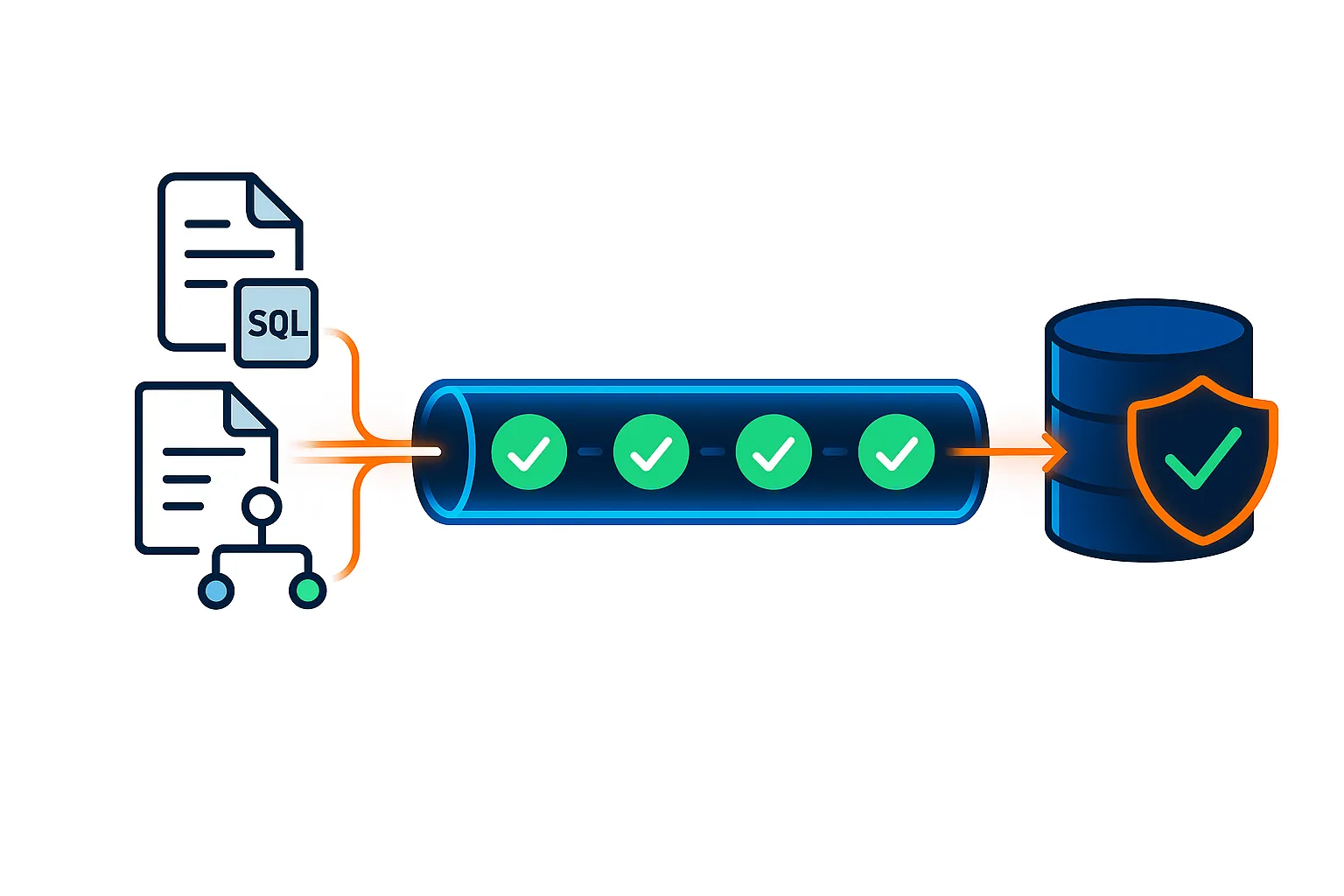
Every stage produces real artifacts and enforces real gates. Nothing is optional.
SQL Compilation
Parse, resolve, generate
SCD Automation
Tag it. We build the MERGE.
30+ Rule Validation
Hard gate before production
Column-Level Lineage
Source to target, every column
Profiling & Baselines
Know your data before you ship
Drift & Health Scoring
Continuous after deployment
BoltPipeline continuously validates SQL pipelines as they are implemented and executed — before anything reaches production.
Your dev, QA, and prd should match. When they don't, you usually find out at deploy time — badly. BoltPipeline compares schemas + data across every environment pair and blocks promotions when divergence exceeds policy.

No other data platform ships this. Schema drift across environments is the silent killer of release confidence. We diff every environment pair on cadence + at promotion time. Block, classify, and remediate — before customers see broken dashboards.
Your data lives across multiple databases. The same customers, orders, and products exist in different places — slightly different names, slightly different types. Until now, finding those overlaps meant months of manual analysis.
BoltPipeline profiles every connected database and automatically identifies duplicate and overlapping objects using deterministic scoring and AI semantic analysis. The result: a clear map of what can be consolidated, what needs migration, and the exact column-level mappings to get there.
No black boxes. Three layers of analysis run on every pair of tables.
Fast, rule-based comparison using structured metadata. No AI needed — pure math.
For ambiguous matches where names differ but meaning aligns. AI resolves what rules can't.
cust_id ↔ customer_identifierFrom scored matches to executable migration artifacts. Ready to run, not ready to guess.
AI can connect to your database — that's easy. But all it sees is table names and column types. Without structured metadata — column roles, SCD strategies, PII classifications, data quality scores, relationship cardinality — AI guesses. Confidently. Incorrectly.
dim_customerid, email, statusvarchar, integer, dateResult: hallucinated SQL that looks right but isn't.
Result: correct SQL, first time. 80+ fields of context.
We bring clarity to your data model. We never see your data. Our agent sends structure and statistics — table names, column types, null rates, uniqueness scores. Never row values. Never PII. Never data previews.
BoltPipeline reduces pipeline failures, review cycles, and operational overhead — while giving leadership confidence that data products are governed, explainable, and safe to scale.
Speed
Weeks to hours
From SQL to certified, production-ready pipelines
Trust
Built in
Certification gates, lineage, and explainers at every stage
Flexibility
No lock-in
SQL-first, portable ANSI artifacts you own
Cost
In-DB only
No external compute, no data movement, fewer incidents
Compliance
By design
Data stays in boundary with audit-ready evidence
Walk through a real pipeline using your schemas and business rules — no migration, no lock-in, no data leaves your database.