Platform Capabilities
BoltPipeline turns SQL business logic into certified, production-ready data pipelines — with correctness, lineage, and governance built in. Write SQL. The platform compiles, validates, and governs. Pipelines run where your data lives.
Seven Pillars, One Platform
Everything you need to go from SQL intent to governed, production-grade data pipelines — without stitching tools together.
SQL-First Automation
Write SQL as intent. BoltPipeline implements the pipeline.
Pre-Deploy Validation
Catch issues before pipelines ever run.
Lineage & Impact
Column-level lineage derived from execution reality.
Drift Detection
Detect schema and data drift before incidents.
Execution Planning
Deterministic, restart-safe execution plans.
Governance by Design
Certification, approvals, and audit trails built in.
Cross-Database Intelligence
Detect duplicates across databases. Plan migrations automatically.
Connecting AI to Your Database Isn't Enough
AI can connect to your database — that's easy. But all it sees is table names and column types. Without structured metadata — column roles, SCD strategies, PII classifications, data quality scores, relationship cardinality — AI guesses. Confidently. Incorrectly.
What AI gets from a raw database
- ✗ Table names:
dim_customer - ✗ Column names:
id, email, status - ✗ Data types:
varchar, integer, date - ✗ No context. No quality. No relationships.
Result: hallucinated SQL that looks right but isn't.
What AI gets from BoltPipeline
- ✓ Column roles: primary key, foreign key, business key
- ✓ SCD strategy: Type 0, 1, or 2 with tracking columns
- ✓ PII classifications, data quality scores, health scores
- ✓ Relationship cardinality, lineage, drift baselines
Result: correct SQL, first time. 80+ fields of context.
We bring clarity to your data model. We never see your data. Our agent sends structure and statistics — table names, column types, null rates, uniqueness scores. Never row values. Never PII. Never data previews.
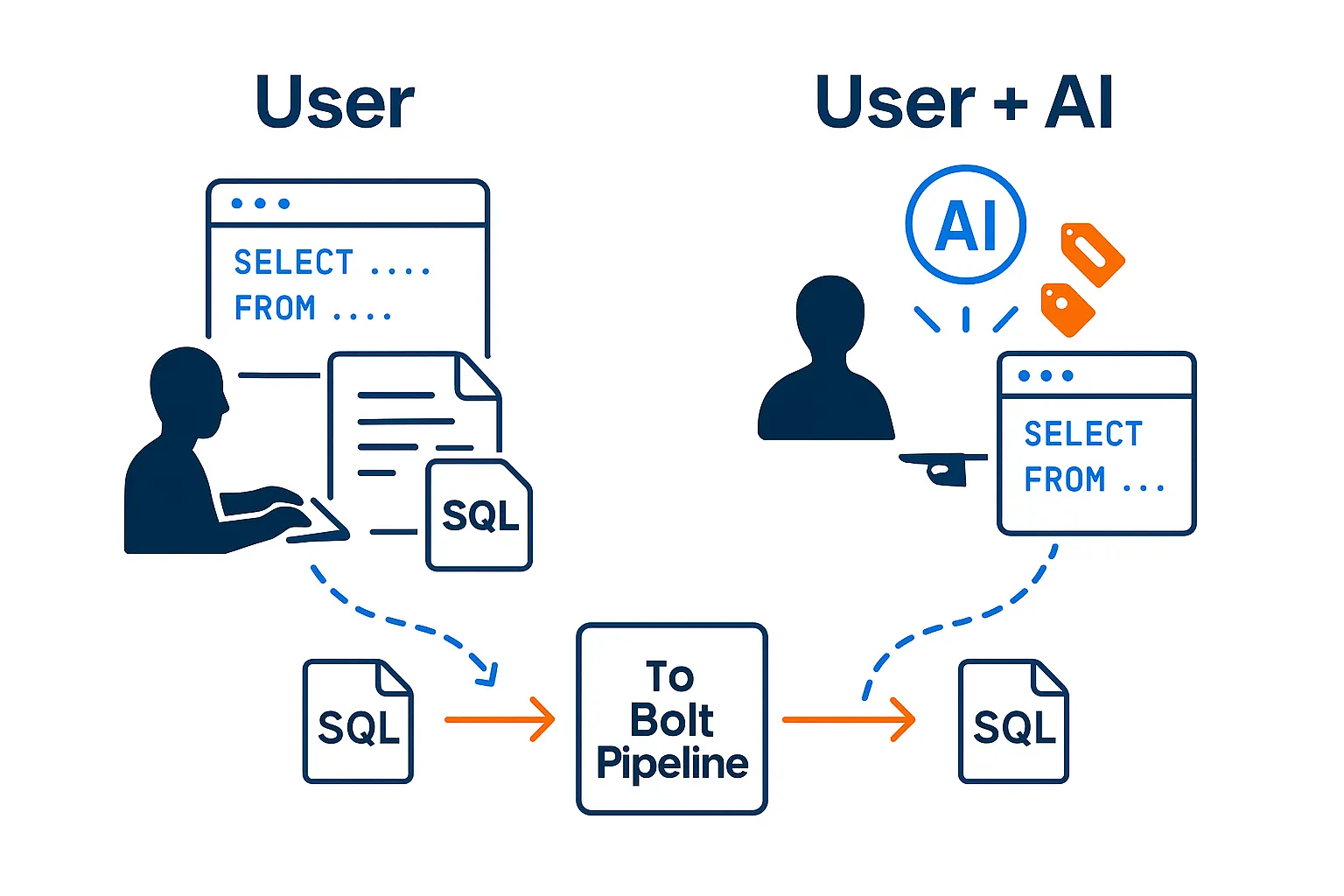
SQL-First Pipeline Automation
BoltPipeline treats SQL as a declarative specification of business intent. Teams continue working in plain SQL while the platform automates the operational heavy lifting.
- No proprietary DSLs or GUIs
- Optional lightweight hints to express expectations
- Git-friendly, CI/CD-ready workflows

Automated Validation & Certification
BoltPipeline validates pipelines before deployment and continuously after release — reducing production risk.
- Schema, type, and compatibility checks
- Join correctness and relationship safety
- Profiling-driven baselines and anomaly detection
Validation results are packaged as certified artifacts for reviews and audits.
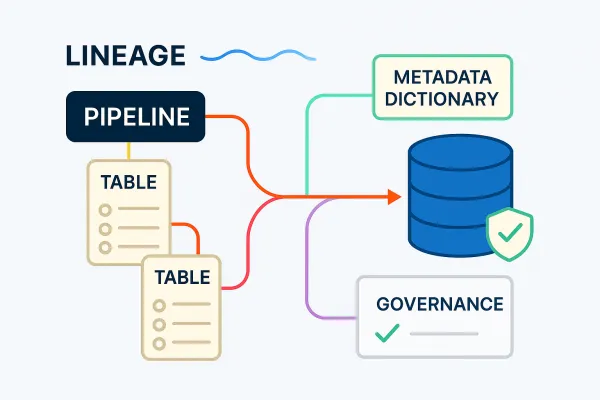
Runtime-Aware Lineage & Impact Analysis
Lineage is derived from actual pipeline behavior, not static documentation.
- Column-level lineage across transformations
- Upstream and downstream impact visibility
- Clear ownership and blast-radius analysis
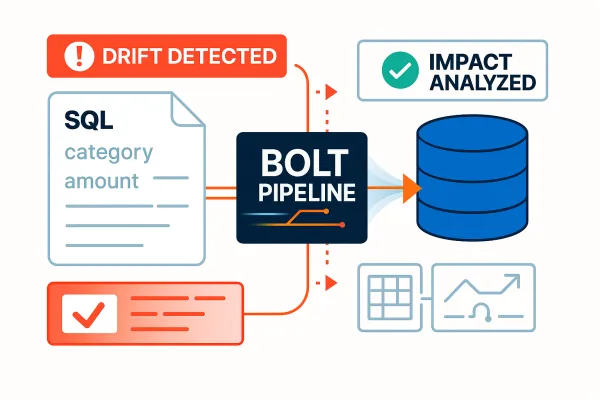
Schema & Data Drift Detection
Data changes are inevitable. Surprises don't have to be.
- Schema evolution detection
- Distribution and behavior drift monitoring
- Early warnings with downstream impact context
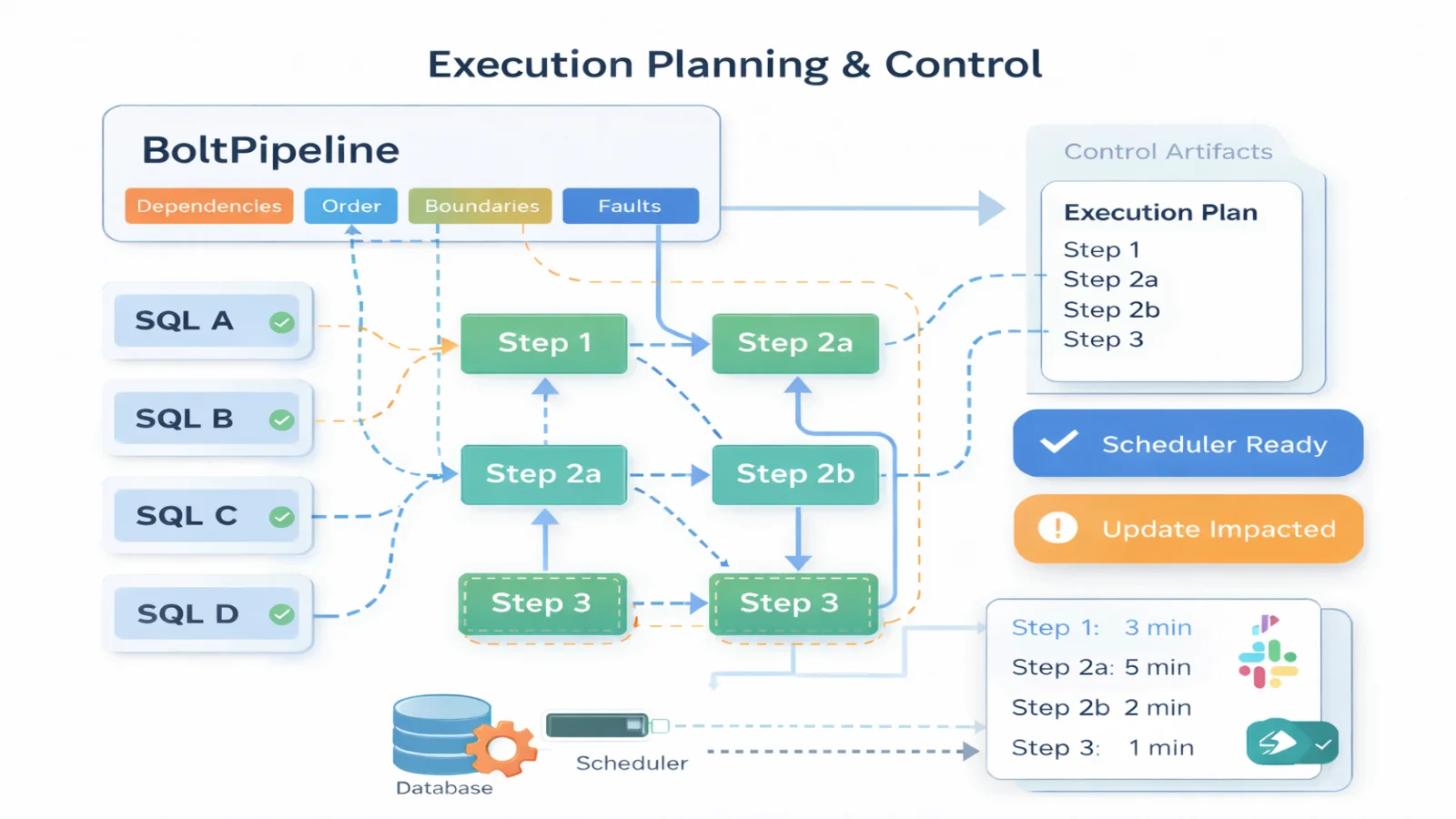
Execution Planning & Control
BoltPipeline derives deterministic execution plans from SQL and rules — without replacing your orchestrator.
- Automatic dependency resolution
- Restart-safe execution boundaries
- Scheduler-agnostic (Airflow, Dagster, etc.)
Cross-Database Intelligence
Your data lives across multiple databases. The same customers, orders, and products exist in different places — slightly different names, slightly different types. Until now, finding those overlaps meant months of manual analysis.
BoltPipeline profiles every connected database and automatically identifies duplicate and overlapping objects using deterministic scoring and AI semantic analysis. The result: a clear map of what can be consolidated, what needs migration, and the exact column-level mappings to get there. These capabilities are not regularly available in the market today.
- Automatic similarity detection across databases
- AI-powered semantic matching for ambiguous column names
- Database-to-database migration with automated DDL and type mappings
- Reconciliation queries to validate data integrity
- Cost optimization — eliminate redundant storage and compute
Coming soon — Roadmap 2026
How It Works
How Cross-Database Intelligence Actually Works
No black boxes. Here's exactly what happens when BoltPipeline analyzes your databases — what data flows where, how scoring works, and what you get at the end.
Data Flow: What Leaves Your Network vs. What Stays
Your Databases
Tables, columns, types, indexes, constraints
🔒 Your network
BoltPipeline Agent
Runs SELECT-only queries. Extracts metadata & stats
🔒 Your network
Scoring Engine
Deterministic scoring + AI semantic analysis
⚡ BoltPipeline
What We See vs. What We Don't
✓What BoltPipeline Receives (Metadata Only)
public.dim_customercustomer_id INTEGER✕What BoltPipeline Never Sees
Sample Similarity Report
Here's what a real cross-database analysis produces — actionable scores you can act on immediately.
| Source Table | Target Table | Overall Score | Column Match | Type Compat. | Stats Match | Recommendation |
|---|---|---|---|---|---|---|
| warehouse_a.dim_customer | warehouse_b.customers | 0.91 | 14/16 cols | 95% | 88% | 🔴 Likely duplicate |
| warehouse_a.fact_orders | warehouse_b.order_history | 0.73 | 9/14 cols | 82% | 71% | 🟡 Overlapping — review |
| warehouse_a.dim_product | warehouse_c.product_catalog | 0.67 | 8/12 cols | 78% | 64% | 🟡 Partial overlap |
| warehouse_a.stg_events | warehouse_b.audit_log | 0.23 | 3/11 cols | 45% | 18% | 🟢 No action |
Scores are composite: table name trigram similarity (15%), column Jaccard overlap (25%), type compatibility (20%), row count proximity (10%), cardinality & null ratio match (20%), AI semantic resolution (10%).
Three-Layer Scoring Engine
Deterministic Scoring
Fast, rule-based comparison using structured metadata. No AI needed — pure math.
- • Table name trigram similarity
- • Column name Jaccard overlap
- • Data type compatibility matrix
- • Row count proximity
- • Cardinality & null ratio matching
AI Semantic Resolution
For ambiguous matches where names differ but meaning aligns. AI resolves what rules can't.
- •
cust_id↔customer_identifier - •
amt↔total_amount - • Semantic type matching (email, phone, address)
- • Business context inference
- • Confidence scoring with explanations
Migration Plan Generation
From scored matches to executable migration artifacts. Ready to run, not ready to guess.
- • DDL scripts with cross-platform type mappings
- • Column-level mapping documentation
- • Reconciliation queries (pre & post migration)
- • Impact analysis on downstream consumers
- • Estimated cost savings from consolidation
Show this to your CISO. BoltPipeline's agent runs inside your network, connects with reader-only credentials, and sends only aggregate metadata over mTLS. No row data. No PII content. No credentials transmitted. The scoring engine works entirely on structure and statistics — the same information your DBA sees in INFORMATION_SCHEMA.
Governance That Ships with the Platform
Every pipeline change is tracked, validated, and approved through the platform. No separate governance tool required.
Audit & Change History
Every pipeline change is tracked with who approved it, when it changed, and why — creating an audit-ready record automatically, without additional tooling.
Operational Visibility
Track pipeline behavior over time using execution signals, validation outcomes, drift events, and historical context — all tied back to certified artifacts.
Stay Ahead with Proactive Alerts
BoltPipeline integrates with the tools teams already use to surface issues early and route them to the right owners.
- Email, webhook, and Slack notifications
- Alerts tied to severity and ownership
- Early warnings before production incidents
Fits Into Your Existing Stack
BoltPipeline works alongside your existing stack — no rip-and-replace required.
- Cloud & enterprise databases
- Airflow, Dagster, schedulers
- Git & CI/CD workflows
- Slack, email, webhook alerts
Ready to See It in Action?
Start your free trial or explore how BoltPipeline works end to end.