LIVE NOW · 4 hands-on labs in under 15 minutes
SQL in.
Certified pipelines out.
Certify it. Run it. Monitor it.
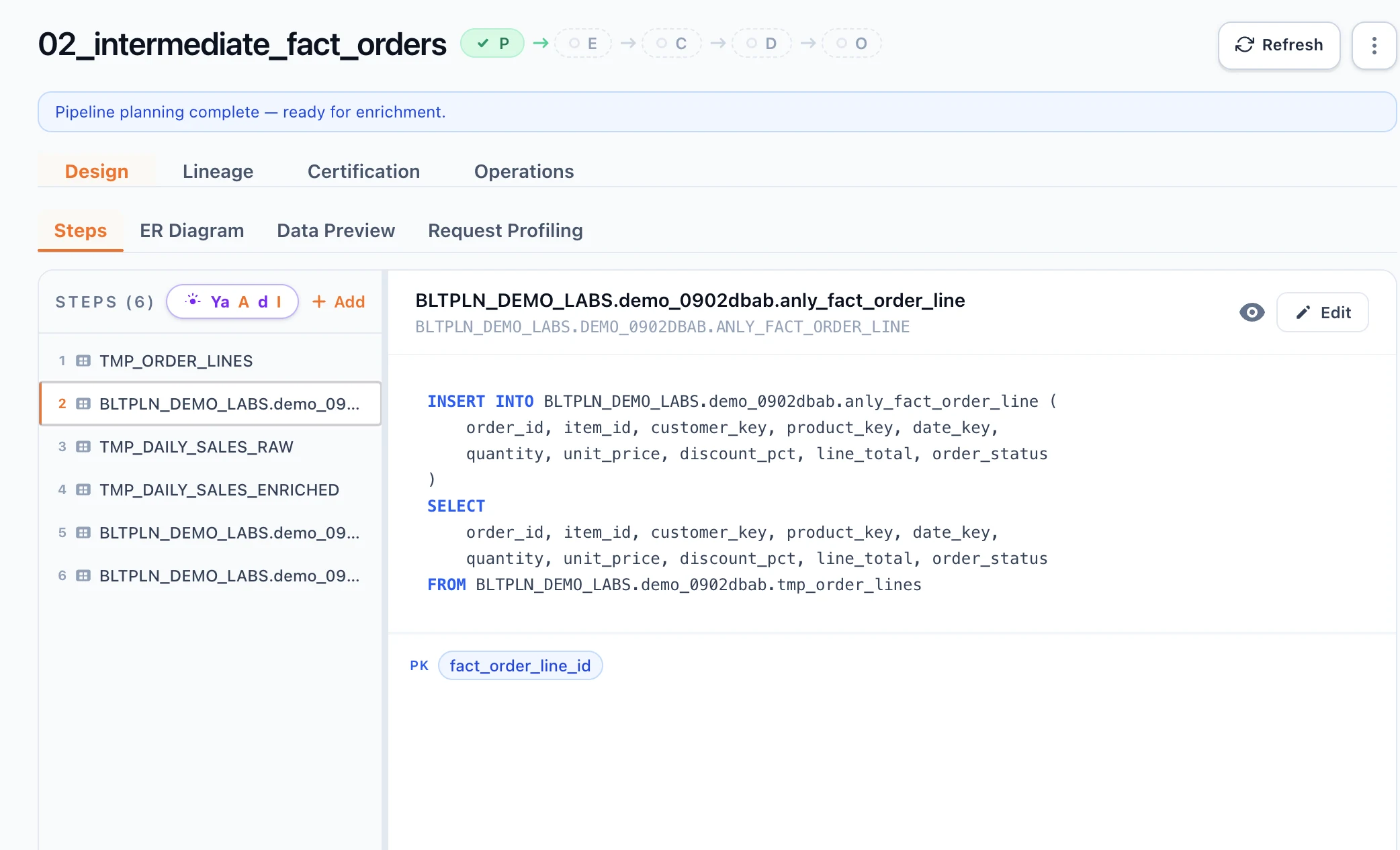
Validate SQL against your live database before deploy.
- 30+ certification rules run against your real schema before deploy
- Column-level lineage + drift detection generated automatically
- Your data never leaves your environment — metadata only
See it in motion
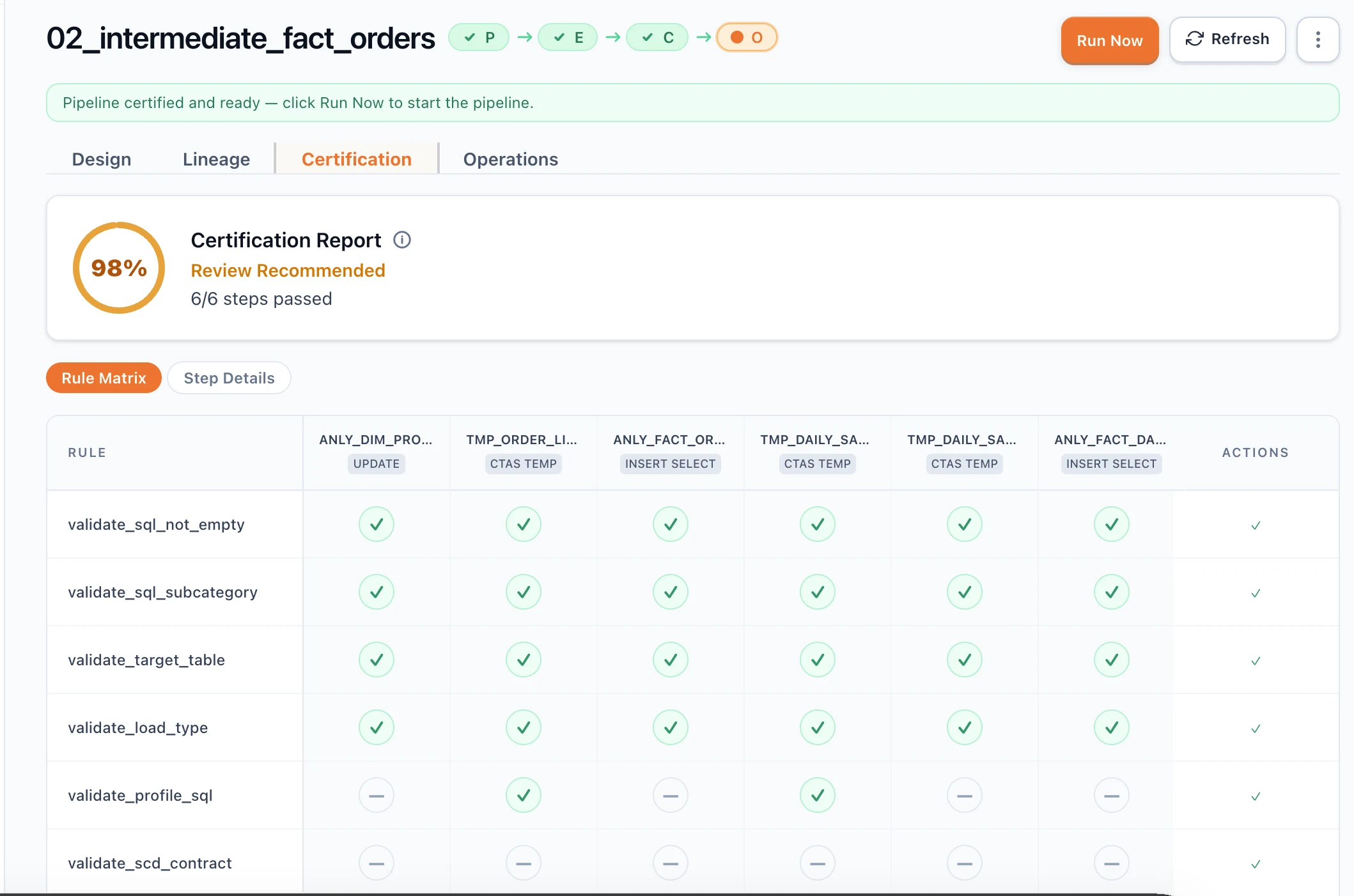
Plan. Certify. Trace. Run.
One pipeline, the full lifecycle — same SQL all the way through.
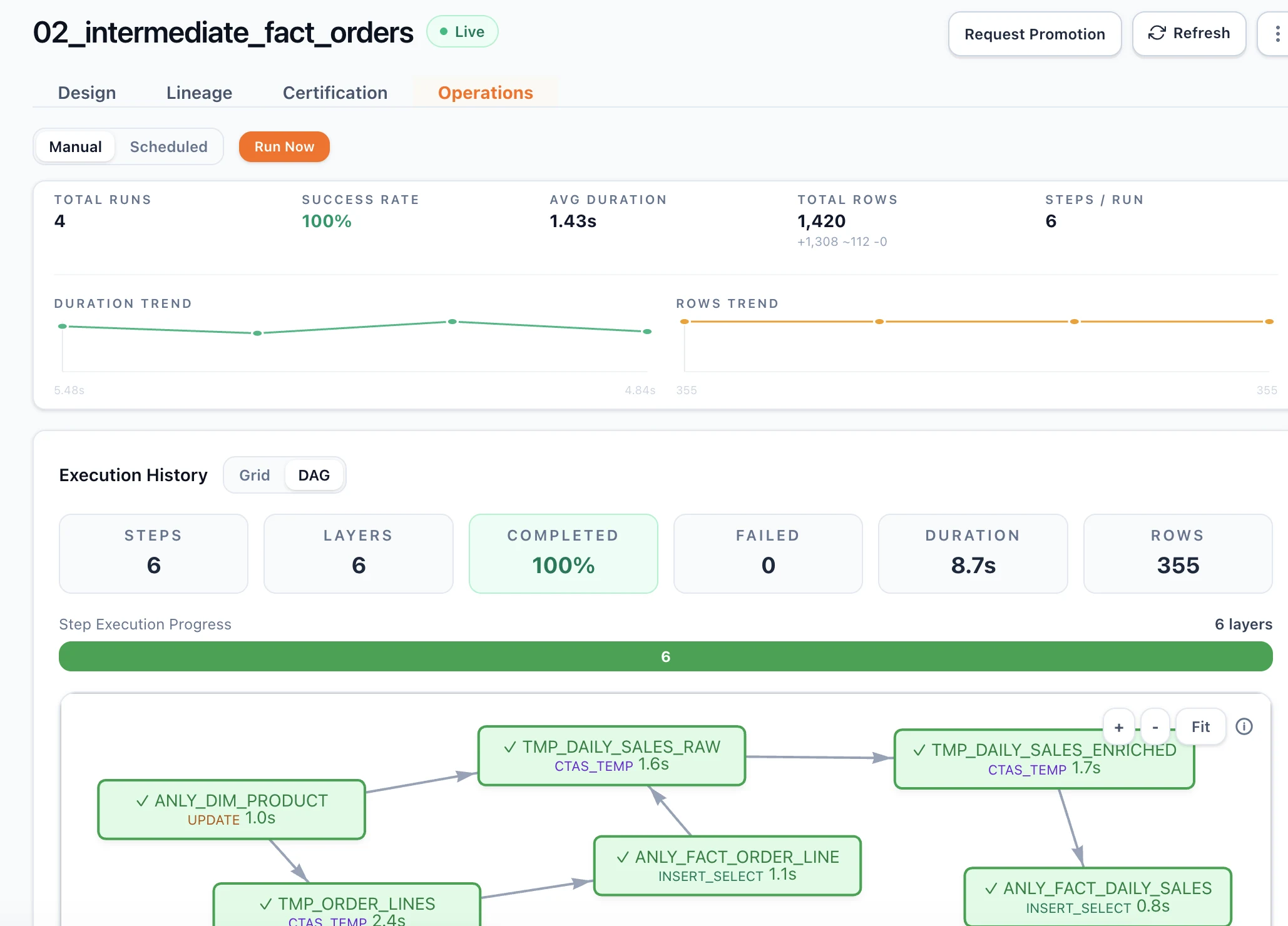

The problem
Your pipelines are walking on glass.
SQL lives everywhere — repos, dashboards, ad-hoc scripts.
Nobody sees the full picture. Schema changes slip through. Failures show up in production.
SQL is scattered
Fragments live in dozens of places. No single source of truth.
Drift is invisible
A column drops, a type flips — nobody knows until production breaks.
Failures happen too late
By the time alerts fire, dashboards are wrong and you’re debugging at 3 AM.
The aha moment
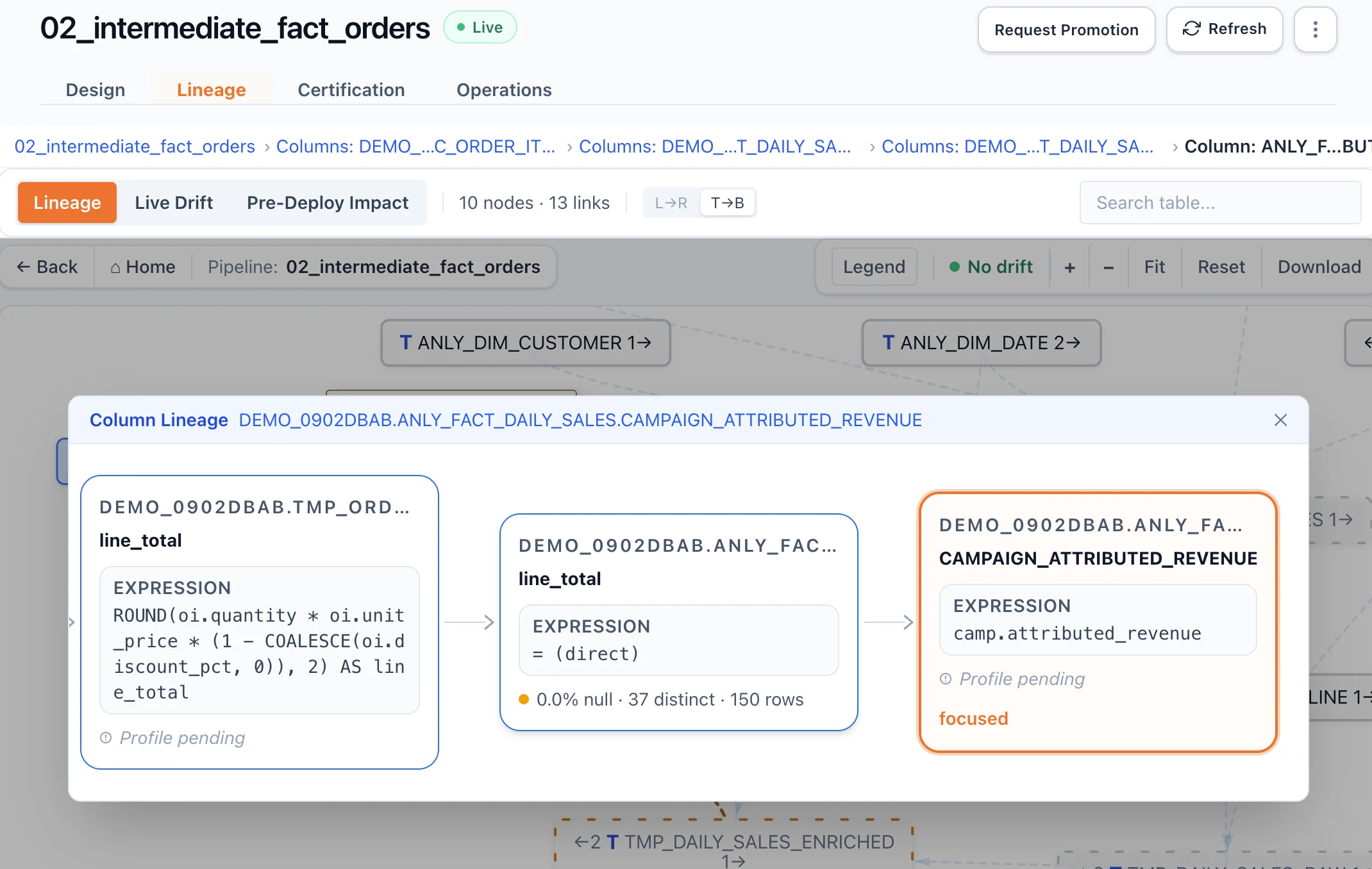
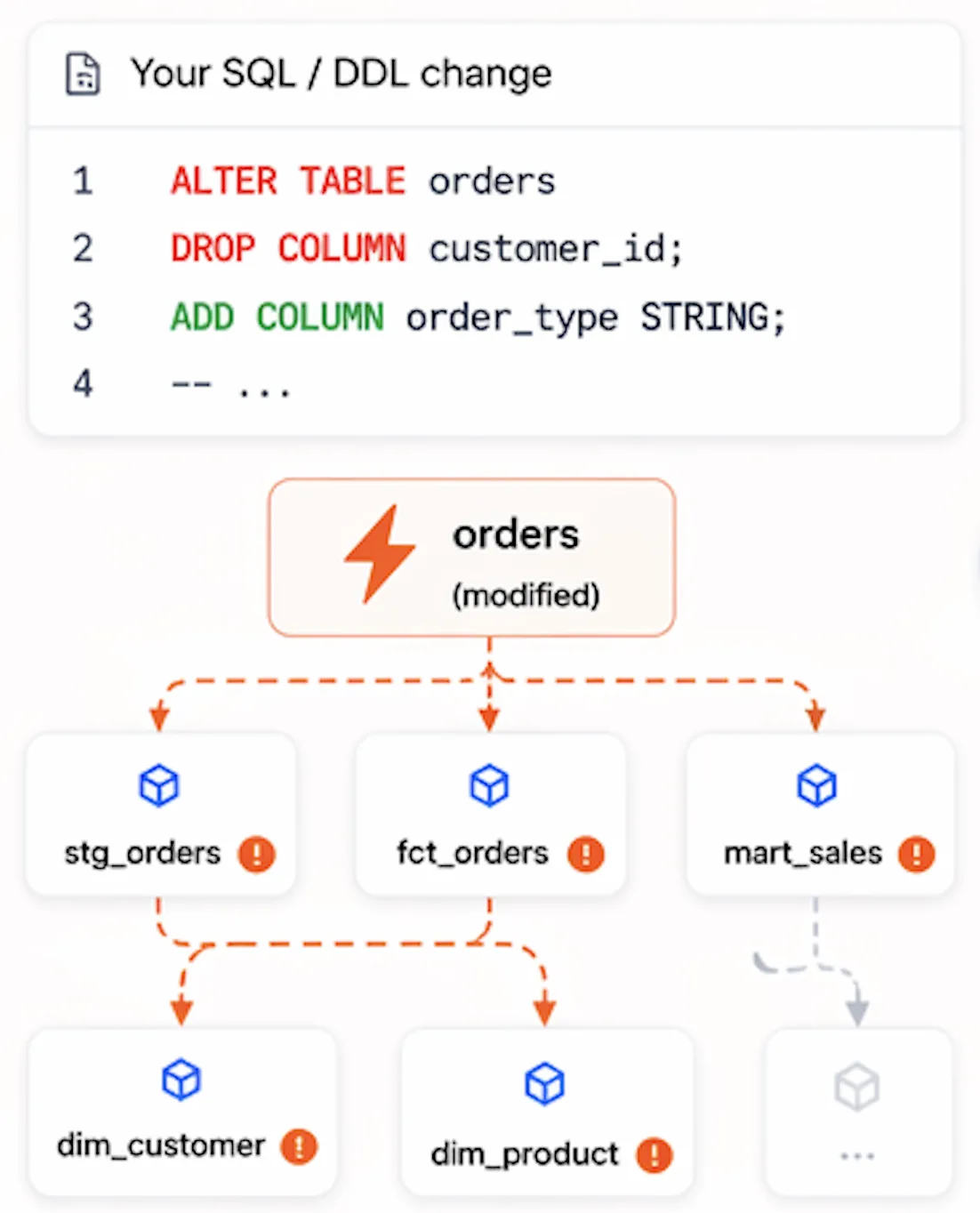
See the blast radius before you deploy.
One SQL change shows every impacted pipeline, table, and dashboard — instantly.
- 3 pipelines break
- 12 downstream tables impacted
- Affects production dashboards
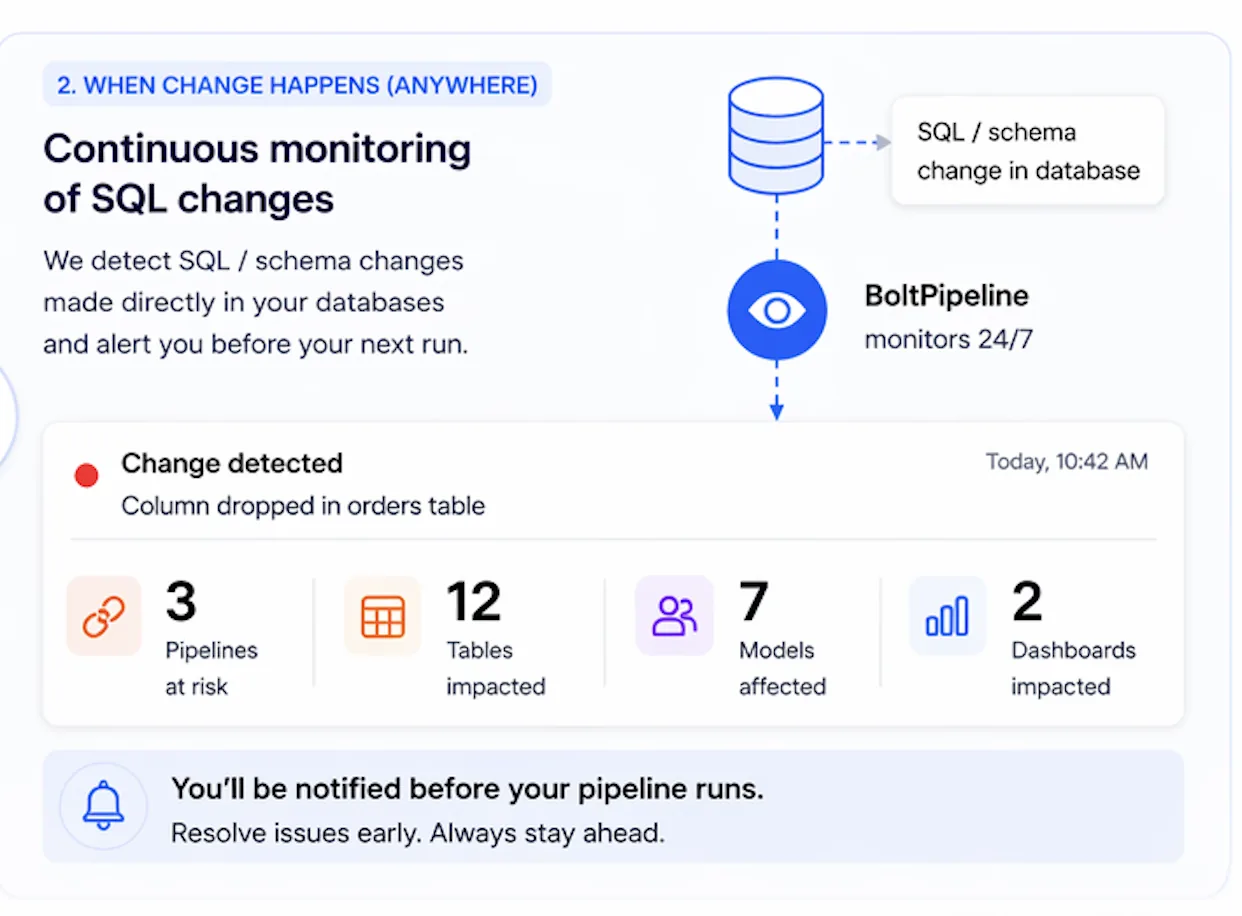
Continuous monitoring
Changes don’t just come from your code.
Schemas change directly in your database.
We detect it and alert you before your next pipeline run.
- Detect schema drift instantly
- See impacted pipelines and dashboards
- Get alerted before execution
Why BoltPipeline is fundamentally different

30+ rule engine validates every pipeline against your live database before deploy. Nothing ships uncertified.
Plan → Enrich → Certify → Operate in one system. No stitching. No gaps.
Every table has one certified producer. SCD rules are validated — not documented.
Execution stays inside your warehouse. We see structure, never rows.
One governed system
One asset. Every role. Same truth.
Every role works on the same governed asset — not copies, not extracts, not separate tools.

Data Engineer
Build certified pipelines
Tester / QA
Validate before promotion
Modeler
Define data contracts
Analyst
Trace any number to source
BI Developer
Build on trusted tables
Operations
Monitor and resolve drift
Governance
Approve and audit changes
Executive
See system health and risk
No stitching. No silos. One system.
Your data never leaves your environment.
BoltPipeline runs inside your warehouse. Our agent sends only structure and aggregates — table names, column types, distributions. Never row values. Never PII. Never data copies.
Runs in your warehouse
Execution stays inside your database.
Metadata only
Aggregates, schemas, distributions — never row values.
Never PII
No row data. No PII. No data copies leave.
Compliance-ready
HIPAA · GDPR · SOC2-ready architecture
Early adopters
Data teams are already running pilots against their live databases.
We're working with a growing group of teams piloting BoltPipeline across Snowflake and PostgreSQL — from analytics consultancies to mid-market platform teams. Customer references and case details available on request.
Request a customer reference →We didn’t build another tool. We built the platform the AI era forces you to have.

When pipelines are generated in seconds, governance has to live in the platform — not in code review, not in conventions, not in tribal knowledge.
Learn about the Enterprise Model →When your champion has to brief the board.
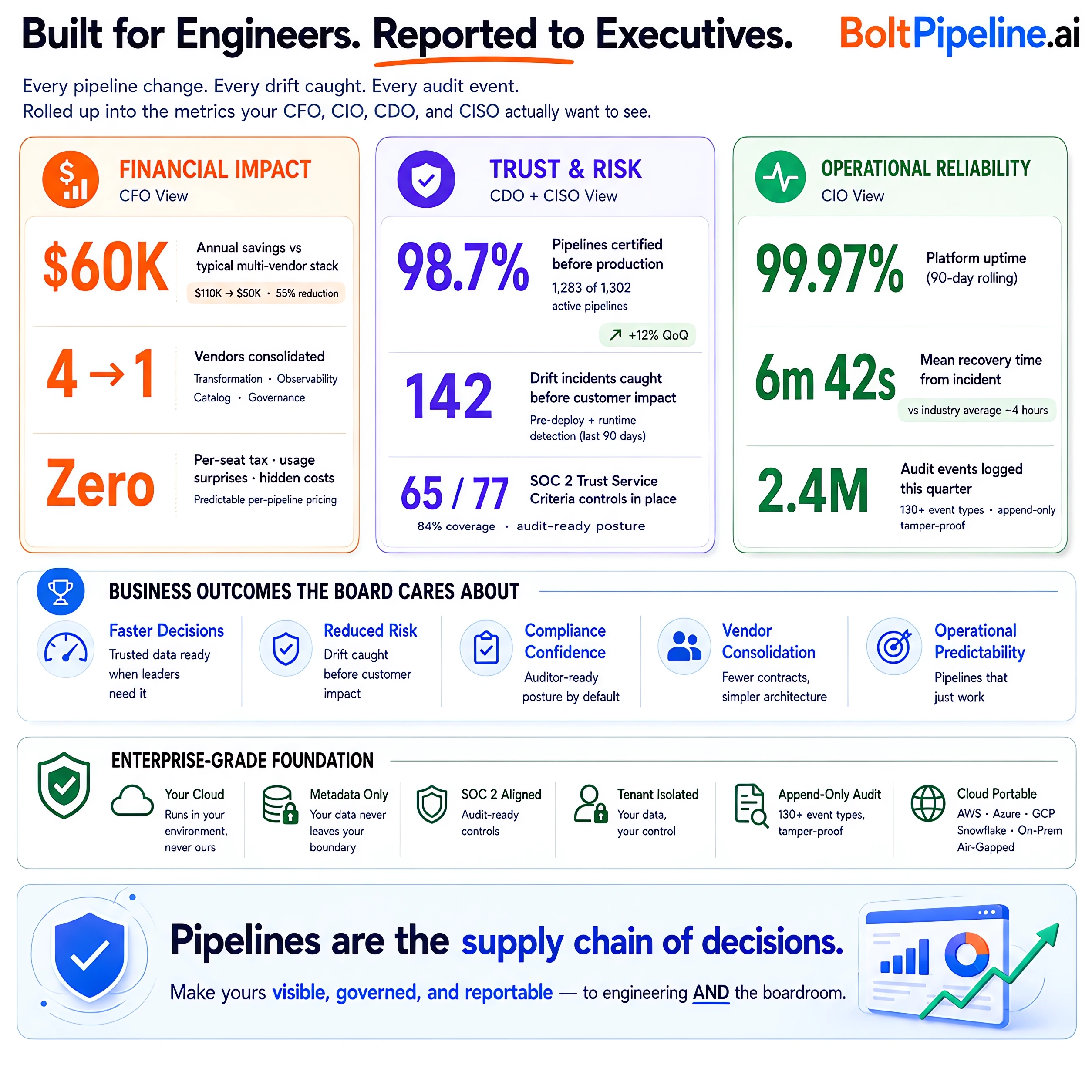
Every pipeline change, every drift caught, every audit event — rolled up into the metrics your CFO, CIO, CDO, and CISO actually want to see.